Repeated Games
From Evolution and Games
This project studies the evolution of cooperation in a repeated prisoner's dilemma with discounting.
Contents |
Run the simulations!
You can download the software here. Once the program is running just click on the big play button to start the fun. Feel free to re-arrange and re-size the windows, zoom-in and out as the program is running. Click here if you need more information about running this program.
The simulation program
What are strategies?
Strategies are either programmed explicitly as finite automata, as regular expressions, or as Turing machines. The set of regular expressions is equivalent to the set of finite automata, but because they are represented differently, the likelihoods of mutations also are different; a mutation that is a single step in one representation requires a series of steps in the other and vice versa.
A finite automaton is a list of states, and for every state it prescribes what the automaton plays when in that state, to which state it goes if the opponent plays cooperate, and to which state it goes if the opponent plays defect.
The simulation
There are N individuals and every generation they are randomly matched in pairs to play the repeated game. The repeated game has a probability of breakdown smaller than 1, hence the number of repetitions is a random variable. The payoffs from the interactions are used in the update step. There are two options; the Moran process and the Wright-Fisher process. In the Moran process, in every generation one individual is chosen to be replaced, and one is chosen to replace. All individuals are equally likely to be chosen to be replaced. Probabilities of being chosen to replace are proportional to fitness. In the Wright-Fisher process all individuals in the new generations are drawn one by one, and independently, from a distribution where, again, the probability of being the offspring of individual j from the old generation is proportional to the payoff of j. The Moran process is extremely inefficient, so we always use the Wright-Fisher process, but the option is there.
After the new generation has been drawn, all individuals have a small and independent probability with which they mutate. There are four types of mutations; mutations that add a state, mutations that delete a state, mutations that change the output when in a state, and mutations that change for a given state to which state this player goes, given an action of the opponent.
This completes the cycle for a generation. The cycle is repeated a large number of times.
Measures of cooperativeness and reciprocity
There are two reasons why we would like to have measures for cooperativeness and reciprocity. The first and most important reason is obvious; we would simply like to know how cooperative, and how reciprocal, strategies are during a run. The second reason is that these measures may serve as an indication of indirect invasions. Typically an indirect invasion is characterized by a change in reciprocity followed by a change in cooperativeness.
Any measure of cooperativeness will have to weigh the different histories, and as we will see, every choice how to weigh them has appealing properties and drawbacks. In contrast to the definitions earlier, here it is more natural to look at histories that only reflect what actions the other player has played. This captures all relevant histories for the measurement of cooperativeness, because what a strategy S itself has played is uniquely determined by the history of actions by the other player.
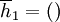
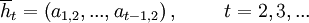
Again, we will sometimes also write 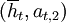 for a history
for a history 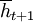 , and we get the following sets of possible histories at time t.
, and we get the following sets of possible histories at time t.
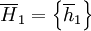

With the repeated prisonners dilemma we have A = C,D, so in that case there are 2t − 1 histories 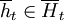
We begin with a measure that tells us how cooperative a strategy is, given that it is facing a history 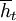 . If we weigh a history at time t + s with the probability that the game actually reaches round t + s − 1, given that it has already reached round t − 1, and if we also divide by the number of different histories of length t + s − 1, under the restriction that the first t − 1 rounds of these histories are given by , we get the following. Note that this measure does not depend on the
environment a strategy is in.
. If we weigh a history at time t + s with the probability that the game actually reaches round t + s − 1, given that it has already reached round t − 1, and if we also divide by the number of different histories of length t + s − 1, under the restriction that the first t − 1 rounds of these histories are given by , we get the following. Note that this measure does not depend on the
environment a strategy is in.
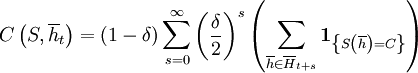
The overall cooperativeness of a strategy S can then be defined as the cooperativeness at the beginning, where we have the empty history; 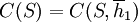 .
.
An intuition for what this measure does can be gained from the following figure. The top bar represents the empty history. The second bar represents histories of length 1, and is split in two; the history where the other has cooperated, and the one where the other has defected. The third bar represents histories of lenth 2, and is split in four; the histories CC, CD, DC and DD. This continues indefinitely, but for the pictures we restrict ourselves to histories of length 5 or less. If a part is blue, then that means that the strategy reacts to this history with cooperation, if it is red, then the strategy reacts with defection. Cooperativeness weighs the blueness of those pictures.

It is obvious that C(AllC) = 1 and that C(AllD) = 0. A strategy that starts with cooperation, and further conditions play on the first move entirely has cooperativeness 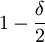 . This is sensible; if δ = 0, then the first move is the
only move, and since this strategy cooperates on the first move, it should have cooperativeness measure 1. On the other hand, except for the first move, this strategy cooperates in exactly half of the histories of length t for all t > 1. Therefore it makes sense that if δ goes to 1, then cooperativeness goes to
. This is sensible; if δ = 0, then the first move is the
only move, and since this strategy cooperates on the first move, it should have cooperativeness measure 1. On the other hand, except for the first move, this strategy cooperates in exactly half of the histories of length t for all t > 1. Therefore it makes sense that if δ goes to 1, then cooperativeness goes to  .
.
More simple computations shows that 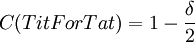 ,
, 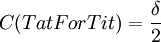 and
and 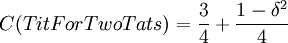 . The last simple computation shows that
. The last simple computation shows that 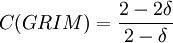 , which is 1 at δ = 0 for similar reasons, and goes to 0 if δ goes to 1.
, which is 1 at δ = 0 for similar reasons, and goes to 0 if δ goes to 1.
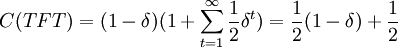
The paper
A version of the paper can be downloaded here The online material that accompanies the paper is here in PDF format.

{kind=link}
{kind=link}